
Use Case
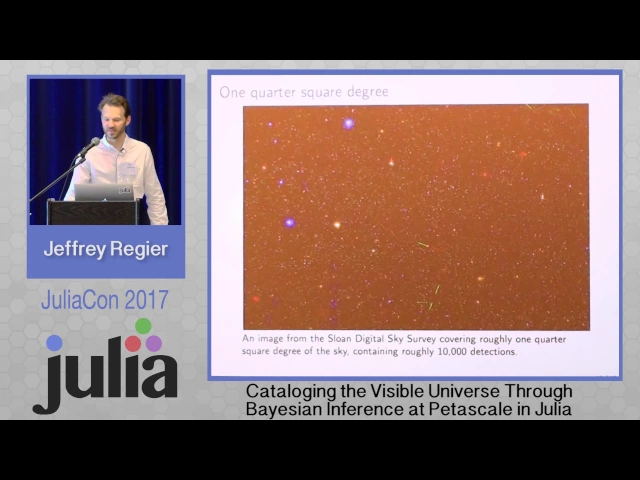
In 1998, the Apache Point Observatory in New Mexico began imaging every visible object from over 35% of the sky in a project known as the Sloan Digital Sky Survey. The images include around 500 million stars and galaxies. Light from the most distant of those galaxies has been traveling for billions of years and lets us see how the universe appeared in the distant past.
For 16 years, the process of cataloging these stars and galaxies was painstaking and laborious.
But in 2014, a team of astronomers, physicists, computer engineers and statisticians began working on the Celeste project.
The Celeste research team spent three years developing and testing a new parallel computing method that was used to process the Sloan Digital Sky Survey dataset and produce the most accurate catalog of 188 million astronomical objects in just 14.6 minutes with state-of-the-art point and uncertainty estimates.
“Celeste brings together a truly unique, multi-institution, multi-disciplinary team,” says Prabhat, Data and Analytics Services Group Lead at the National Energy Research Scientific Computing Center (NERSC) at Lawrence Berkeley National Laboratory (Berkeley Lab). “We have world-class physicists and astronomers at Berkeley Lab working hand-in-hand with top-notch statisticians and machine learning experts at UC Berkeley and Harvard. They have access to performance tuning and scaling experts at Intel, Julia Computing and MIT and to Cori, one of the world’s most powerful supercomputers, located at NERSC.”
The Celeste team set a number of new milestones, including:
Loaded an aggregate of ~178 terabytes of image data and produced parameter estimates for 188 million stars and galaxies in 14.6 minutes
Written entirely in Julia, a new high-level programming language, and achieved a peak performance of 1.54 petaflops using 1.3 million threads on 9,300 Knights Landing (KNL) nodes of the Cori supercomputer at NERSC
Achieved a performance improvement of 1,000x in single-threaded execution
Demonstrated conclusively that massive and complex datasets can be analyzed with Bayesian inference by applying variational inference (VI)
Provided not only point estimates for light sources but, for the first time, a principled measure of the quality of inference for each light source (posterior uncertainty for source type, brightness, and colors)
“In addition to predicting each light source's location, brightness, color, type, and morphology, Celeste quantifies the uncertainty of its predictions,” explains Jeff Regier, postdoctoral researcher in UC Berkeley’s Department of Electrical Engineering and Computer Sciences. “Both the predictions and the uncertainties are based on a Bayesian model, inferred by a technique called variational Bayes. To date, Celeste has estimated more than 8 billion parameters based on 100 times more data than any previous reported application of variational Bayes."
“There are currently about 200 supercomputers in the world that are capable of delivering peak flops of more than a petaflop per second, the so-called ‘petaflop club’,” says Pradeep Dubey, Intel Fellow and Director of the Parallel Computing Lab at Intel. “However, pretty much all applications capable of achieving a petaflop per second are written by a group of ninjas who have a deep understanding of both the application domain and the lowest level of system software and hardware details that matter for performance. Celeste is now a member of this very exclusive group of applications, but with a unique distinction - this is the first such application written entirely in Julia. This sets a new industry high on the performance-plus-programmer-productivity spectrum. Celeste is an outstanding example of a high performance computing application that solves a real-world problem, and demonstrates a bright future for Julia in high performance computing. We believe the techniques we developed can be applied successfully to other problems using Julia together with high performance computing, parallel computing and/or multithreading capabilities.”
When the Julia project got started in 2009, the project's goal of unifying high performance and high productivity “seemed like a far-off dream,” adds Keno Fischer, CTO at Julia Computing. “In 2017, projects like Celeste show that this dream has become a reality. Scientists can now take the prototypes they have developed on their laptops and run them on the biggest supercomputers without having to switch languages or completely rewrite their code. We are very proud of this accomplishment and confident that Julia will help advance the frontier of scientific discovery for many years to come.”
According to NERSC scientist Rollin Thomas, exascale systems at facilities like NERSC are now less than a decade away. “This will be a tremendous opportunity for both complex simulation workloads and big data for science,” Thomas said. “But programming exascale systems is expected to be challenging. New programming models and high-level languages like Julia may address this exascale programmability gap. The problem is figuring out how to keep the language expressive and abstract but achieve levels of performance usually only available to programmers by discarding abstraction. Celeste, which involved key contributions from core language developers, shows how Julia aspires to solve this problem. At NERSC we are watching to see whether the Julia effort can put the same kind of feat as Celeste within reach of the average programmer."
The Celeste research team is already looking to new challenges. For example, the Large Synoptic Survey Telescope (LSST), scheduled to begin operation in 2019, is 14 times larger than the Apache Point telescope and will produce 15 terabytes of images every night. This means that every few days, the LSST will produce more visual data than the Apache Point telescope has produced in 20 years. With Julia and the Cori KNL supercomputer, the Celeste team can analyze and catalog every object in those nightly images in as little as 5 minutes. The Celeste team is also working to:
Further increase the precision of point and uncertainty estimates
Identify ever-fainter points of light near the detection limit
Improve the quality of native code for high performance computing
What does all this mean for science? Here are a few possibilities:
Celeste is creating the most accurate map of the universe. What can this map be used for?
Maps are necessary for navigation and exploration of our place in the universe relative to other celestial objects.
Maps that extend to these far reaches in the universe are essentially a time machine, allowing us to see the universe as it appeared in the distant past.
Dark matter and dark energy influence the time history of the universe, and its eventual fate. Starting in 2019, galaxies from these maps will be targeted with the Dark Energy Spectroscopic Instrument.
Celeste is being expanded to take time into account. This will make it possible to detect planets, including planets that could contain life.
Celeste is also being expanded to detect asteroids that could be on a collision course with Earth. Once detected, we can prepare an appropriate response, such as a mission that would cause the asteroid’s path to deviate in order to avoid hitting Earth.
In the future we would like to apply this modeling to all galaxies in a set of time-domain surveys and look for new point sources at or near the core of the galaxies where difference imaging, a standard technique for finding astrophysical transients, often fails,” explains Peter Nugent, Senior Scientist and Division Deputy for Science Engagement in the Computational Research Division at Berkeley Lab. “This will aid in the detection of and characterization of time-evolving sources such as tidal disruption events and gravitationally lensed supernovae. These have the potential of transformative improvements in our understanding of supermassive black holes, dark matter and cosmology.
David Schlegel, Senior Scientist in the Berkeley Lab Physics Division, adds,
Our ability to map larger volumes of the universe has been scaling with Moore's Law, but our ability to analyze those data hasn't kept up. The Celeste project is a big leap forward to try to get there.
The Celeste project is a shining example of:
High performance computing applied to real-world problems
Cross-institutional collaboration including researchers from UC Berkeley, Lawrence Berkeley National Laboratory, National Energy Research Scientific Computing Center (NERSC), Intel, Julia Computing and the Julia Lab at MIT
Cross-departmental collaboration including astronomy, physics, computer science, engineering and mathematics
Julia, the fastest modern open source high performance programming language for scientific computing
Parallel and multithreading supercomputing capabilities
Public support for basic and applied scientific research
Prabhat concludes:
Celeste is a huge leap forward. We combined the speed of Julia with one of the world’s most powerful supercomputers to set a new performance record and solve a real-world problem. When the LSST begins producing data in two years time, Celeste will be even faster, more accurate and more advanced. Celeste remains number one on our Top Ten List of Big Data Problems for a good reason.







